Abstract
mask rcnn 是在 Faster r-cnn 基础上增加了一个 mask预测分支,因此被命名
检测速度大概 在 5fps
mask rcnn 也适用于其他任务,如人体姿态估计
Introduction
视觉社区在很短的时间内,对目标检测和语义分割的结果进行了迅速改进。
在很大程度上,这些进步是由强大的 baseline system 驱动的,例如,Fast/Faster R-CNN 和 FCN 分别用于物体检测和语义分割。这些方法在概念上是直观的,并提供了灵活性和稳健性,同时还有快速的训练和推理时间。我们在这项工作中的目标是开发一个具有可比性的框架,以实现实例分割。
实例分割是具有挑战性的,因为他不仅需要正确的检测出图片中的目标,还要精准地分割每一个实例。它结合了 目标检测(对单个目标进行分类,并使用边界框对每个对象进行定位)和语义分割(目标是将每个像素分类到一组固定地类别,没有区分物体的实例)
我们的方法被称为Mask R-CNN,通过增加一个预测分割掩码的分支来扩展Faster R-CNN[29],每个感兴趣的区域(RoI),与现有的用于分类和边界盒回归的分支并行(图1)。掩码分支是一个应用于每个RoI的小型FCN,以像素对像素的方式预测一个分割掩码。考虑到Faster R-CNN框架,Mask R-CNN的实现和训练都很简单,这有利于广泛的灵活架构设计。此外,掩码分支只增加了少量的计算开销,使快速系统和快速实验成为可能。
原则上,Mask R-CNN是Faster R-CNN的一个直观的扩展,然而正确地构建掩码分支对于良好的结果至关重要。最重要的是,Faster R-CNN不是为网络工作输入和输出之间的像素对齐而设计的。这一点在RoIPool 中最为明显,它是关注实例的事实上的核心操作,为特征提取进行粗略的空间量化。为了解决错位问题,我们提出了一个简单的、无量化的层,称为RoIAlign,忠实地保留了精确的空间位置。【对齐特征层,并对特征层进行 精细地 裁剪 resize】
尽管似乎是一个很小地改变,但 RoIAlign 却影响巨大,将 mask 地准确率相对提升了10%到 50%,在严格地定位指标下 显示出更大的收益
其次,作者认为 将类别预测和掩码预测 进行解耦 十分重要:mask rcnn 为每一个类别独立预测一个二进制掩码,类别之间没有竞争,依靠 RoIclassification 分支来预测类别。相比之下,FCN 通常进行逐像素的多类分类,这种分割于分类相结合,从我们的实验来看,实例分割的效果很差
mask rcnn 每帧 200ms 在一块 GPU上,训练 COCO 任务 在一个 8GPU的服务器上用了1-2天
mask rcnn 还进行了 coco的关键点任务
Related Work
R-CNN:基于区域的CNN 方法,用于对边界框目标检测,关注一定可管理数目的候选目标区域,然后在每一个个ROI上独立进行 卷积网络评估。R-CNN被扩展允许对特征图上ROI使用ROIpool,提高了速度和精度。Faster r-cnn 通过 区域提议网络 RPN 注意力机制,推进了这一进程。Faster R-CNN 是灵活和鲁棒行的,对于之后的许多改进,是目前几个基准中领先的框架
Instance Segmentation,受到R-CNN高效性的驱动,许多用于实例分割的方法基于 segment proposal,【举例子。。。。】
最近,Li等,将 segment proposal 系统和目标检测系统 结合在 fully convolution instance segmentation FCIS 中。共同的思想是 【完全卷积地预测一组位置敏感地输出通道,这些通道可以同时处理物体类别,边界框,mask,使得系统快速】。但是 FCIS 在 重叠地实例上表现出系统错误,并产生了虚假地边,表明它受到了实例分割地基础行困难
Mask R-CNN
Mask R-CNN 在概念上很简单。Faster R-CNN对每个候选对象都有两个输出,一个类标签和一个bounding-box offset;为此我们增加了第三个分支,输出对象掩码。因此,Mask R-CNN是一个自然和直观的想法。但是,额外的掩码输出与类别和边界框输出不同,需要提取物体的更多精细的空间布局。接下来,我们介绍Mask R-CNN的关键元素,包括像素到像素的对齐,这是Fast/Faster R-CNN的主要缺失部分。
Faster R-CNN,简单回顾一下 Faster R-CNN,其由两部分组成。第一阶段,区域提议网络 RPN,提取 候选的物体边界框。第二阶段,实质上是 Faster R-CNN 使用 ROIPool 从每一个候选框中提取特征,并进行分类和边界框回归。被两个阶段使用的特征可以被共享 用于更快的推断。
Mask R-CNN ,采用了相同的两阶段,第一阶段是相同的 RPN 网络,在第二阶段,在预测类别和box offset 的同时,Mask R-CNN 也输出一个 二值的 mask 为每一个 ROI。 这和大多数最近胸痛相反,他们的分类依靠 mask 预测。我们的方法 遵循 Faster R-CNN的 精神,即并行应用边界框分类和回归,其证明 很大程度上简化了 原始 R-CNN的多阶段 pipeline
形式上,我们定义了一个多任务损失 在每一个 ROI上
$L = L{cls}+L{box}+L_{mask}$
我们对mask loss的定义允许网络为每个类别生成mask,而不需要在类别之间进行竞争;我们依靠专门的分类分支来预测用于选择输出掩码的类别标签。解耦掩码和类别预测。这与将FCN应用于语义分割时的常见做法不同,后者通常使用per pixel sigmoid 和一个 multinomial cross-entropy损失。在这种情况下,不同类别的掩码会相互竞争;在我们的案例中,对于每像素的sigmoid 和一个 binary loss,它们不会。我们通过实验表明,这种形式化是获得良好实例分割结果的关键。
Mask Representation:一个mask 编码一个输入物体的空间布局。因此,不像 被 全连接层 不可避免 折叠成短的 输出向量的 类别标签 或者 边界框偏移, 可以通过卷积提供的像素对像素的关系自然解决
具体来说,我们使用FCN从每个RoI预测一个m×m 的mask。这使得掩码分支中的每一层都能保持明确的m×m 目标空间布局,而不需要将其折叠成缺乏空间维度的向量表示。与之前借助fc layers进行掩膜预测的方法不同,我们的全卷积表示法需要更少的参数,而且更准确,正如实验所证明的那样。
这种像素到像素的行为要求我们的RoI特征(本身就是小的特征图)能够很好地对齐,以忠实地保留明确的每像素空间对应关系。这促使我们开发了以下RoIAlign 层,它在掩码预测中起着关键作用。
为了解决这个问题,我们提出了一个RoIAlign 层,它重新移动了RoIPool的苛刻量化,使提取的特征与输入正确对齐。我们建议的变化很简单:我们避免对RoI边界或bin进行任何量化(即我们使用x/16而不是[x/16] 【没有把浮点数 变成 整数】)。我们使用双线性插值[18]来计算每个RoI bin中四个有规律采样的位置 的输入特征的精确值,并将结果汇总(使用最大或平均)。【使用双线性插值来 对 bin 中选取的 四个 位置 计算特征精确值,再用 平均或者取最大 来得到 bin 中的精确的输入特征值】

RoIAlign导致了很大的改进。我们还与[7]中提出的RoIWarp操作进行了比较。与RoIAlign不同,RoIWarp忽略了对齐问题,在[7]中被实现为像RoIPool一样对RoI进行量化。因此,尽管RoIWarp也采用了由[18]激发的双线性重采样,但它的表现与RoIPool相当,正如实验所显示的那样(更多细节见表 2c),证明了对齐的关键作用。
Network Architecture : 为了证明我们方法的通用性,我们将Mask R-CNN 实例化为多架构。为了清楚起见,我们区分了:(1)用于对整个图像进行特征提取的卷积骨架,以及(2)分别应用于每个RoI的边界盒识别(分类和回归)和掩码预测的网络头。
使用了不同的 backbone:resnet-50,resnet-101,resnext-50,resnext-101;
使用了不同的 head Architecture:Faster RCNN使用resnet50时,从Block 4导出特征供RPN使用,这种叫做ResNet-50-C4
作者使用除了使用上述这些结构外,还使用了一种更加高效的backbone:FPN(特征金字塔网络)
对于网络头,我们严格遵循以前工作中提出的架构,其中我们增加了一个完全卷积的掩码预测分支。具体来说,我们对ResNet[15]和FPN[22]论文中的Faster R-CNN盒头进行了扩展。详情见图3。ResNet-C4骨干网的头部包括ResNet的第5阶段(即9层的Latherres5推理[15]),这是计算密集型的。对于FPN,骨干网已经包括了res5,因此可以得到一个更有效的头,使用更少的过滤器。
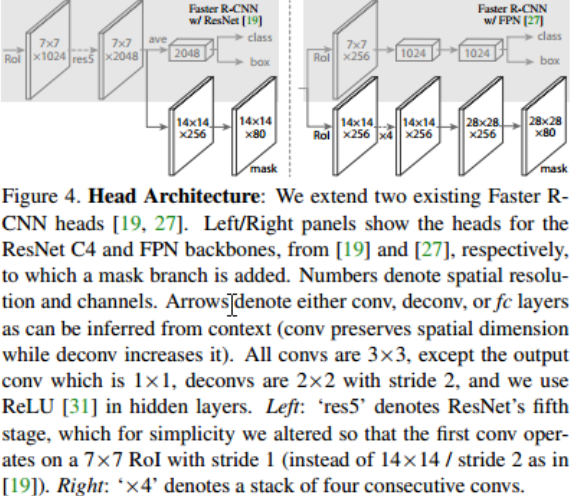
我们注意到,我们的掩码分支有一个straight forward 直接的结构。更复杂的设计有可能提高性能,但不是这项工作的重点。
Implementation details
我们按照现有的Fast/FasterR-CNN工作[9,29,22]设置超参数。尽管这些决定是在原始论文[9,29,22]中为物体检测做出的,但我们发现我们的实例分割系统对它们是稳健的。
training :与快速R-CNN一样,如果一个RoI的IoU与ground truth 框至少为0.5,则被认为是积极的,否则就是消极的。掩码损失loss mask只定义在阳性RoI上。掩码目标是RoI和其相关的地面真实掩码之间的交集。
我们采用以图像为中心的训练[9]。图像被调整大小,使其比例(短边缘)为800像素[22]。每个mini-batch每个GPU有2张图像,每张图像有N个采样的RoI,阳性与阴性的比例为1:3
C4骨干网的N 是 64和 FPN 是 512。我们在8个GPU上训练(所以有效的 ,mini-batch为16),进行16万次迭代,学习率为0.02,在12万次迭代时减少10。我们使用0.0001的权重衰减和0.9的动量。
RPN 锚 跨越 5个尺度和3个长宽比。为了方便消融实验,RPN是单独训练的,不与Mask R-CNN共享特征,不明确。对于本文中的每个entry,RPN 和Mask R-CNN都有相同的骨干,因此它们是可共享的。
Inference :在测试时,C4骨干网的 proposal number 为300,FPN为1000 。我们在这些建议区域上运行box预测分支,然后进行非最大抑制[11]。然后,mask分支被应用于得分最高的100个检测盒。尽管这与训练中使用的并行计算不同,但它加快了推理速度并提高了准确性(由于使用了更少、更准确的RoI)。mask分支可以预测每个RoI的k个mask,但我们只使用第k个mask,即分类分支预测的类别。然后,m×m floating-number mask 输出被调整为RoI大小,并以0.5的门槛进行二进制化。
注意,由于我们只在前100个检测框上计算掩码,Mask R-CNN对其Faster R-CNN counterpart(例如,在典型模型上∼20%)增加了少量开销。
Experiments: Instance Segmentation
Mask R-CNN for Human Pose Estimation
略
Mask head 代码
Mask R-cnn 的 mask 分支【代码来源于 mmdetection】
# mask head config
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=256,
conv_out_channels=256,
num_classes=80,
loss_mask=dict(
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))
# mask head forward()
for conv in self.convs:
x = conv(x)
if self.upsample is not None:
x = self.upsample(x)
if self.upsample_method == 'deconv':
x = self.relu(x)
mask_preds = self.conv_logits(x)
return mask_preds在 mask 分支上 仍然是 进行多次卷积,然后进行一次上采样,【到这里依然是特征图】最后得到 各个类的mask 是将特征图 送入一个 conv_logits() 函数得到
logits是指未归一化的对数概率。也就是说,logits是一个向量,它的每个元素表示某个类别的对数概率,但是这些元素的和不一定等于1。通常,logits会作为输入传给一个归一化函数,比如softmax函数,来得到每个类别的概率。
self.conv_logits = build_conv_layer(self.predictor_cfg, logits_in_channel, out_channels, 1)
# self.conv_logits = build_conv_layer('Conv', logits_in_channel, out_channels, 1)可以看到,conv_logits 也是一个 卷积层,参数为 输入的 通道数,输出通道数,1 应该为卷积核 size
