
2024年的最后一天,回顾今年 读研 上半年结束了之前的研一的二维项目D1,整个项目期间出差次数估计10+,出差天数25+ 同时因为无知入坑另外一个三维项目T1(项目还未启动) 参与另外一个三维项目T2,项目现状,按合同应该是要交付,但因部分算法精度无法达到,以及部分新增需求未完成(与我无关),进展缓慢,处于搁置状态;我在里面大概承担了2-3个需求,大概占项目任务的25%~35% T2由一个博士带队,最初包括我在内2个研究生负责业务算法,以及两位工程师,分别负责软硬件集成,后续陆续拉进来2~3人,人数最多时有4名研…

唯爱与美食不可辜负 记录一下自己吃过的东西(泡面、酒...) 泡面 白象香菜面 辣牛肉底味,香菜味直接闻不到,吃到嘴里还可以 5元/盒(我看到有超市卖到8元/盒,amazing) 千里薯板面 6元/盒, !!!!是我吃过最好吃的板面泡面!!!! 海底捞番茄粉 8元/盒 阿宽面皮(麻酱味) 5元/盒 阿宽面皮(酸辣味) 5元/盒 酒 天地一号苹果醋 均价3元/瓶 pxx 15瓶/46 !!!好喝的,微微的气泡感,还有苹果的味道!!! 哈尔滨啤酒 4元/瓶 迷失海岸 12-14元/瓶 气泡水 塞浦路斯气泡水5-10元/…

在这里写一些关于博客的计划 太忙了,太忙了....... 欢迎大家留言提出建议 最新动态 2024-03-18 小站启用wpdisuz评论系统 2024-01-16 小站 加入 开往, 2024-01-01 最新的群号:392784757,欢迎你找到我们 2023-11-29 设置当前文章排序 基于修改时间 显示,方便更新原来的文章 字帖项目下线了 抱歉 2023-06-23 整了一个导航页,主要是一些文档,工具类的网站导航, 点击这里直达 cC'nav 很久以前 2022-07-26 我的记录模块新增 《我的观影…

解决方案 解决方案来自 https://github.com/NVIDIA/TensorRT/issues/1714 pybind11-stubgen --ignore-all-errors tensorrt_bindings 这个是针对特定版本 8.6.1 才有的,由NVIDIA提供 在pypi上NVIDIA还提供了一些 bindings 应该是用来支持更新版本的TensorRT 安装 pybind11-stubgen 和 tensorrt_bindings pip install pybind11-stubge…
五年前购买服务器到期,618入手一台99元每年的服务器 比我之前的配置还是高了不少 2核 3Mb 实例迁移 整体过程参考 https://help.aliyun.com/zh/smc/user-guide/migrate-servers-between-ecs-instances 主要是在SMC迁移工作台上完成 服务器迁移-->导入迁移源 导入后进入迁移配置项, 选择先演练(会进行验证,失败不会进行后续迁移)再迁移策略,其他基本默认即可 验证时需要账号余额>100元 这个过程会创建临时实例(应该是涉及到…

项目一览 以开源项目 cloudcompare 为例,一个大型项目 肯定会有很多模块,每个模块 根据需求 生成 dll 库 或者 lib 库 主程序 dll 库 lib库 debug 模式调试 编译生成,运行 提示找不到 运行依赖的dll 查找相应项目库的路径 可以看到是已经编译生成了的 只不过 和我们的 exe 不在同文件夹下 此时 我们可以选择安装,或者调整输出目录 中间目录输出 先看一下xx.dir/[debug/release] 下有什么 日志 以及 .obj 文件 方案A 安装法 安装后我们的exe 以及…

在这个AI时代,NVIDIA是无法绕开的一个公司(国内外大公司也都在追赶构建自己的软硬件生态,毫无疑问还需要时间,可以拭目以待),我们使用它们的硬件GPU,使用他们的SDK,让我们在这个AI时代得以构建更加强大的模型和应用。NVIDIA 提供了广泛的开发库,以下是我们收集整理的一些主要和常用的 NVIDIA 开发库(陆续更新中): CUDA (Compute Unified Device Architecture) CUDA 是 NVIDIA 推出的并行计算平台和编程模型,它允许开发者使用 C、C++ 等语言编写程…
前言 书接上文 OCR实践—PaddleOCR Table-Transformer 与 PubTables-1M table-transformer,来自微软,基于Detr,在PubTables1M 数据集上进行训练,模型是在提出数据集同时的工作, paper PubTables-1M: Towards comprehensive table extraction from unstructured documents,发表在2022年的 CVPR 数据来自 PubMed PMCOA 数据库的 一百万个 文章表格 …

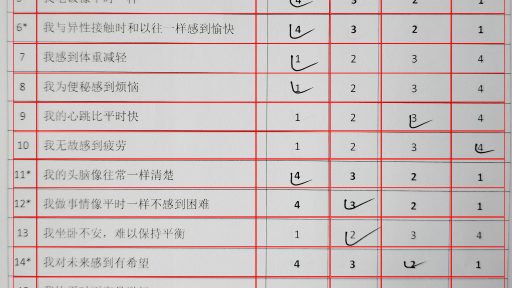
有个项目需求,对拍摄的问卷图片,进行自动得分统计【得分是在相应的分数下面打对号】,输出到excel文件 原始问卷文件见下图,真实的图片因使用手机拍摄的图片,存在一定的畸变, 技术调研 传统方法 传统方法,通过线检测 先对 表格进行矫正【仿射变换】,然后二次线检测 划分出不同表格cell,然后根据位置关系 拿到得分区的cell,利用统计手段或其他手段判断是否存在对号,同时得分区存在逆序关系,即有的问题是从 1-4,有的则是4-1,这样就需要对第一个数字区cell 即起始数字进行判断 是 1 or 4 深度学习方法OC…
十年之约 & 开往